Case study: data leakage#
This case study illustrates the use of the staircase package to simplify feature engineering while avoiding data leakage. Data leakage, also known as target leakage, occurs when models are trained and validated using data that would not, and will not, be available at the time of prediction. In order to avoid data leakage it is important to think about the time at which that data becomes known.
The dataset used in this example is taken from Kaggle and is distributed under a creative commons license. If you’ve ever looked at buying real estate it is likely you have investigated property prices in the same neighbourhood as a guide to estimating price. It is therefore tempting, when using this dataset for predicting house price, to use average sale price in the neighbourhood as an input feature. The problem is that when predicting a price for a particular house that is yet to be sold, we will not know the price it sold for (obviously) or the price for any house that sells after it. The data used to train a machine learning model must reflect this. We can still engineer an average house price feature for each house, however in order to avoid data leakage it can only use prices for houses sold prior to that house. This can be a tricky, or inefficient, calculation however staircase can make light work of this.
We begin by importing the house price data into a pandas.DataFrame instance. Each row corresponds to a house that has been sold. There are many columns, however for this exercise we are only interested in Suburb, Price, and Date. The Date column does not appear to have a time component (i.e. hour/minute/second) but staircase could have handled this.
In [1]: import pandas as pd
In [2]: import staircase as sc
In [3]: import matplotlib.pyplot as plt
In [4]: from matplotlib.dates import MonthLocator, DateFormatter
In [5]: data = pd.read_csv(house_data, parse_dates=['Date'], dayfirst=True)
In [6]: data
Out[6]:
Suburb ... Propertycount
0 Abbotsford ... 4019.0
1 Abbotsford ... 4019.0
2 Abbotsford ... 4019.0
3 Abbotsford ... 4019.0
4 Abbotsford ... 4019.0
... ... ... ...
13575 Wheelers Hill ... 7392.0
13576 Williamstown ... 6380.0
13577 Williamstown ... 6380.0
13578 Williamstown ... 6380.0
13579 Yarraville ... 6543.0
[13580 rows x 21 columns]
Whenever there is date/time data in a dataset there are immediately step functions which spring to life. For example, in this dataset the following are variables which can be calculated:
the number of houses sold, up to a particular point in time
the number of houses sold in Abbotsford, up to a particular point in time
the number of houses with more than 2 bathrooms sold, up to a particular point in time
the total sum of house prices, up to a particular point in time
As these variables change as time moves along, they give rise to step functions. For example, at the time a house is sold the value of the step function corresponding to “number of houses sold” increases by one, and the value of the step function corresponding to “total sum of house prices” increases by the price of the house. We can take these two step functions and divide them to get another which will describe the average house price over time - this is what we are aiming to calculate.
We can create the step function for number of houses sold by simply passing the Date column to the staircase.Stairs constructor as the start times of intervals. There are no end times, as once a house changes state from “unsold” to “sold”, it never becomes “unsold” again.
In [7]: houses_sold = sc.Stairs(data, start="Date")
We can create the step function for total sum of house prices similarly, however this time we set the value argument to be the house price column, so that the step function increases by the house price at each sale date.
In [8]: sum_houses_prices = sc.Stairs(data, start="Date", value="Price")
Let’s plot these:
In [9]: fig, axes = plt.subplots(nrows=2, figsize=(10,5), sharex=True)
In [10]: houses_sold.plot(axes[0]);
In [11]: axes[0].set_title("Number of houses sold over time");
In [12]: sum_houses_prices.plot(axes[1]);
In [13]: axes[1].set_title("Sum of houses prices sold over time");
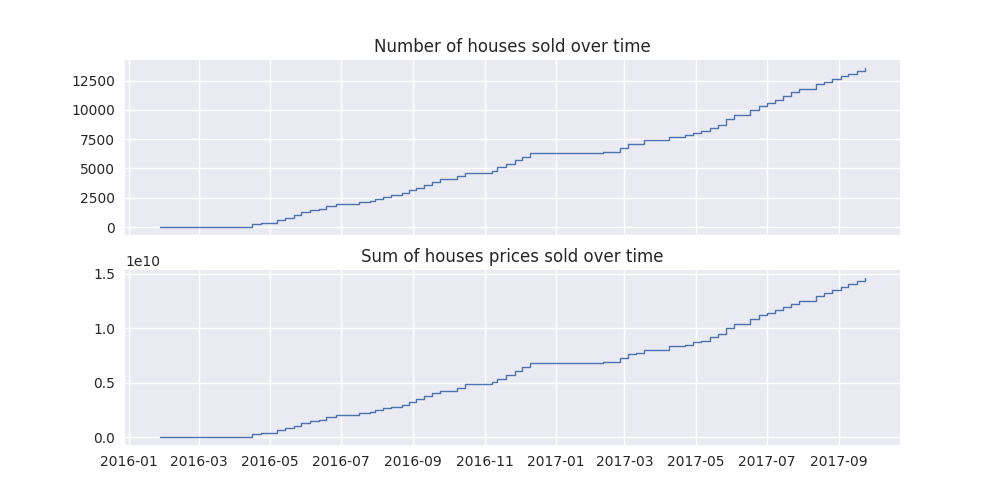
These step functions look to be almost identical, albeit one scaled much higher, however their quotient will tell a different story. We now divide these step functions to obtain one for average house price over time
In [14]: fig, ax = plt.subplots(figsize=(10,3))
In [15]: av_house_prices = sum_houses_prices/houses_sold
In [16]: av_house_prices.plot(ax);
In [17]: ax.set_title("Average houses price over time");
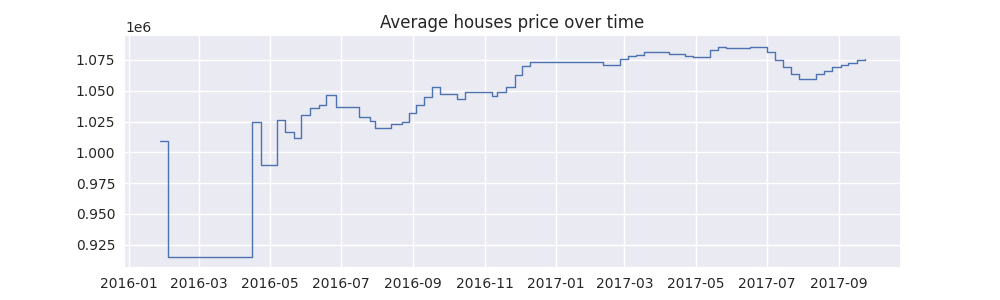
As can be seen from the plot, as time goes on the average is less variable. It settles down as more and more houses are taken into account when calculating the average. It is also possible to calculate rolling averages too, whether by a fixed number of previous houses, or with a time based rolling window, eg “previous month”. This will be discussed later.
So how do we get use this information in our training set? If a house is sold on a particular date then we want to know the average house price up until that point. Given the date in our dataset are at the day level it is sufficient to examine the value of the step function half a day earlier. For each of our houses, we can calculate this date like so:
In [18]: sample_times = data["Date"] - pd.Timedelta(0.5, "day")
In [19]: sample_times
Out[19]:
0 2016-12-02 12:00:00
1 2016-02-03 12:00:00
2 2017-03-03 12:00:00
3 2017-03-03 12:00:00
4 2016-06-03 12:00:00
...
13575 2017-08-25 12:00:00
13576 2017-08-25 12:00:00
13577 2017-08-25 12:00:00
13578 2017-08-25 12:00:00
13579 2017-08-25 12:00:00
Name: Date, Length: 13580, dtype: datetime64[ns]
So these are the times at which we need to know the value of our av_house_prices step function. We can get these values by simply “calling” our step function as if it was a method:
In [20]: av_price_samples = av_house_prices(sample_times)
In [21]: av_price_samples
Out[21]:
array([1062574.85372665, 1009000. , 1075649.66444543, ...,
1066004.48268084, 1066004.48268084, 1066004.48268084],
shape=(13580,))
At the moment this data is a numpy array, but we can add it to our original dataset.
In [22]: data["average_price"] = av_price_samples
In [23]: data.head()
Out[23]:
Suburb Address ... Propertycount average_price
0 Abbotsford 85 Turner St ... 4019.0 1.062575e+06
1 Abbotsford 25 Bloomburg St ... 4019.0 1.009000e+06
2 Abbotsford 5 Charles St ... 4019.0 1.075650e+06
3 Abbotsford 40 Federation La ... 4019.0 1.075650e+06
4 Abbotsford 55a Park St ... 4019.0 1.030348e+06
[5 rows x 22 columns]
To recap, creating the average house price data feature is as simple as
In [24]: sample_times = data["Date"] - pd.Timedelta(0.5, "day")
In [25]: data["average_price"] = (
....: sc.Stairs(data, start="Date", value="Price") /
....: sc.Stairs(data, start="Date")
....: )(sample_times)
....:
Now, for the houses sold on the earliest date in this dataset there will be no average house price data, and there will be missing values in the average_price column for these houses. These values would need to be imputed before proceeding. The average_price column can then be used as an input to a machine learning model.
Next we explore some advanced usage with staircase.
Sampling the step function “immediately to the left”
We took a shortcut above, by the fact that our dates were at the day-frequency level, and we sampled the step function the day before each sale. What if we wanted the values of the step function up until the exact date? This can be done with the staircase.Stairs.limit() method, which takes sample points and a side parameter.
In [26]: pd.Series(
....: av_house_prices.limit(sample_times, side="left")
....: )
....:
Out[26]:
0 1.062575e+06
1 1.009000e+06
2 1.075650e+06
3 1.075650e+06
4 1.030348e+06
...
13575 1.066004e+06
13576 1.066004e+06
13577 1.066004e+06
13578 1.066004e+06
13579 1.066004e+06
Length: 13580, dtype: float64
A step function per suburb
We calculate a pandas.Series indexed by suburb, whose values are step functions (staircase.Stairs). Using this we can calculate average house prices (up to a certain point in time) for each suburb.
In [27]: def create_av_price_step_function(df):
....: count = sc.Stairs(df, start="Date")
....: sum_prices = sc.Stairs(df, start="Date", value="Price")
....: return sum_prices/count
....:
In [28]: data.groupby("Suburb").apply(create_av_price_step_function)
Out[28]:
Suburb
Abbotsford <staircase.Stairs, id=124855313279248>
Aberfeldie <staircase.Stairs, id=124855313231824>
Airport West <staircase.Stairs, id=124855451339344>
Albanvale <staircase.Stairs, id=124855329473936>
Albert Park <staircase.Stairs, id=124855452042128>
...
Wonga Park <staircase.Stairs, id=124855007080848>
Wyndham Vale <staircase.Stairs, id=124855011806992>
Yallambie <staircase.Stairs, id=124855326543504>
Yarra Glen <staircase.Stairs, id=124855451780304>
Yarraville <staircase.Stairs, id=124855025218064>
Length: 314, dtype: object
Rolling average using time window
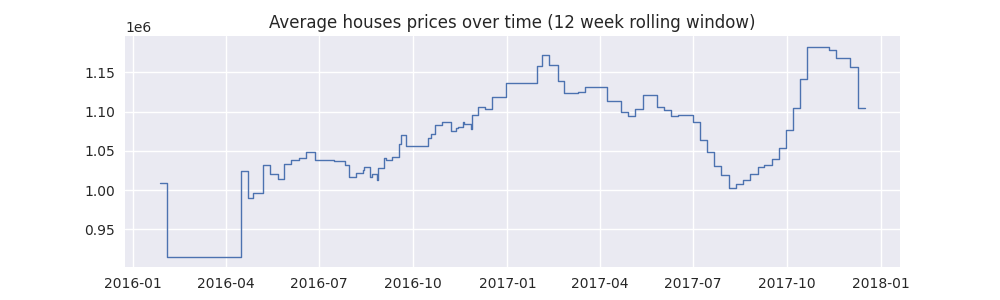
In this example the calculate the average house price, however it only takes into account houses from the past 12 weeks.
In [29]: time_window = pd.Timedelta(12, "W") # 12 weeks
In [30]: expiry = data["Date"] + time_window
In [31]: count = sc.Stairs(data, start="Date", end=expiry)
In [32]: sum_prices = sc.Stairs(data, start="Date", end=expiry, value="Price")
In [33]: av_house_prices = sum_prices/count
In [34]: fig, ax = plt.subplots(figsize=(10,3))
In [35]: av_house_prices.plot(ax);
In [36]: ax.set_title("Average houses prices over time (12 week rolling window)");