staircase.sample¶
-
staircase.sample(collection, points=None, how='right', expand_key=True)¶ Takes a dict-like collection of Stairs instances and evaluates their values across a common set of points.
Technically the results of this function should be considered as \(\lim_{x \to z^{-}} f(x)\) or \(\lim_{x \to z^{+}} f(x)\), when how = ‘left’ or how = ‘right’ respectively. See A note on interval endpoints for an explanation.
Parameters: - collection (dictionary or pandas.Series) – The Stairs instances at which to evaluate
- points (int, float or vector data) – The points at which to sample the Stairs instances
- how ({'left', 'right'}, default 'right') – if points where step changes occur do not coincide with x then this parameter has no effect. Where a step changes occurs at a point given by x, this parameter determines if the step function is evaluated at the interval to the left, or the right.
- expand_key (boolean, default True) – used when collection is a multi-index pandas.Series. Indicates if index should be expanded from tuple to columns in a dataframe.
Returns: A dataframe, in tidy format, with three columns: points, key, value. The column key contains the identifiers used in the dict-like object specified by ‘collection’.
Return type: pandas.DataFrameSee also
Examples
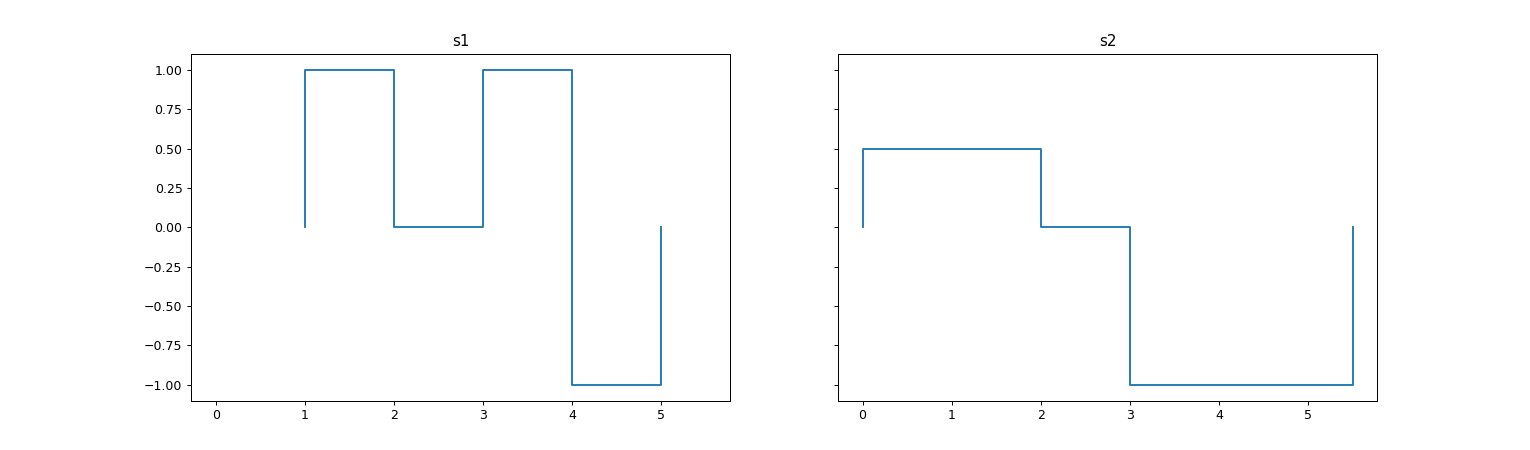
>>> stair_list = [s1, s2] >>> fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(17,5), sharey=True, sharex=True) >>> for ax, title, stair_instance in zip(axes, (['s1', 's2']), stair_list): ... stair_instance.plot(ax) ... ax.set_title(title)
>>> sc.sample({"s1":s1, "s2":s2}, [1, 1.5, 2.5, 4]) points key value 0 1.0 s1 1.0 1 1.5 s1 1.0 2 2.5 s1 0.0 3 4.0 s1 -1.0 4 1.0 s2 0.5 5 1.5 s2 0.5 6 2.5 s2 0.0 7 4.0 s2 -1.0